RISC V は、カリフォルニア大学バークレー校によって開発された命令セット アーキテクチャです。 RISC の概念は、ほとんどのプロセッサ命令がほとんどのコンピュータ プログラムで利用されていないという事実に基づいています。そのため、不必要なデコード ロジックが設計内で使用されていました。 プロセッサ 、より多くの電力と面積を消費します。命令セットを短縮し、レジスタ リソースにより多く投資するには、 RISC V プロセッサ 実施されました。
このテクノロジーは、完全にオープンソースで無料であるため、多くのテクノロジー大手や新興企業に注目されました。ほとんどのタイプのプロセッサはライセンス契約で利用できますが、このタイプのプロセッサでは使用できません。誰でも新しいプロセッサの設計を行うことができます。そのため、この記事では、RISC V プロセッサの概要、つまり動作とそのアプリケーションについて説明します。
RISC Vプロセッサとは?
RISC V プロセッサでは、RISC という用語は、コンピュータ命令をほとんど実行しない「縮小命令セット コンピュータ」を表し、「V」は第 5 世代を表します。これは、確立された原則に基づくオープンソースのハードウェア ISA (命令セット アーキテクチャ) です。 危険 .
他の ISA 設計と比較して、この ISA はオープン ソース ライセンスで利用できます。そのため、多くの製造会社が、オープンソースのオペレーティング システムを備えた RISC-V ハードウェアを発表し、提供しています。
これは新しいアーキテクチャであり、オープンで制限のない無料のライセンスで利用できます。このプロセッサは、チップおよびデバイス メーカー業界から幅広いサポートを受けています。そのため、多くのアプリケーションで使用できるように、主に自由に拡張およびカスタマイズできるように設計されています。
RISC Vの歴史
RISC は、カリフォルニア大学バークレー校の David Patterson 教授によって 1980 年頃に発明されました。 David 教授と John Hennessy 教授は、「Computer Organization and Design」と「Computer Architecture at Stanford University」という 2 冊の本に取り組みを提出しました。それで、彼らはACM A.M.を受け取りました。 2017年のチューリング賞。
1980 年から 2010 年にかけて RISC 第 5 世代の開発研究が開始され、最終的にリスク 5 と発音される RISC-V として特定されるようになりました。
RISC V のアーキテクチャと動作
RV12 RISC V アーキテクチャを以下に示します。 RV12 は、組み込み分野で使用されるシングルコア RV32I および RV64I 準拠の RISC CPU で高度に構成可能です。 RV12 は、業界標準の RISC-V 命令セットに応じて、32 ビットまたは 64 ビットの CPU ファミリーにも属します。
RV12 は、ハーバード アーキテクチャを実行するだけで、命令とデータ メモリに同時にアクセスできます。また、実行間のオーバーラップを最適化するのに役立つ 6 ステージのパイプラインと、効率を向上させるためのメモリ アクセスも含まれています。このアーキテクチャには、主に分岐予測、データ キャッシュ、デバッグ ユニット、命令キャッシュ、およびオプションの乗算器または除算器ユニットが含まれます。
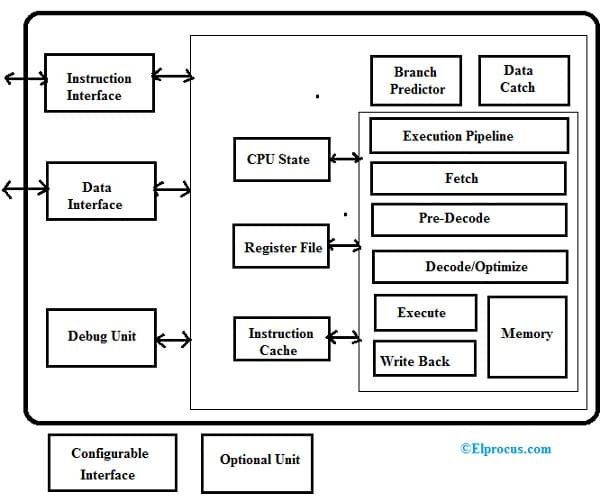
RV12 RISC V の主な機能は次のとおりです。
- 業界標準の命令セットです。
- 32 ビットまたは 64 ビットのデータでパラメータ化されます。
- 正確で高速な割り込みがあります。
- カスタム命令により、独自のハードウェア アクセラレータを追加できます。
- シングルサイクルの実行。
- 折りたたみを最適化する 6 段階のパイプライン。
- メモリ保護をサポート。
- オプションまたはパラメーター化されたキャッシュ。
- 非常にパラメータ化されています。
- ユーザーは 32/64 ビット データと分岐予測ユニットを選択できます。
- ユーザーは、命令/データ キャッシュを選択できます。
- ユーザーが選択可能なキャッシュの構造、サイズ、およびアーキテクチャ。
- ユーザー定義のレイテンシによるハードウェア除算器または乗数のサポート。
- バス アーキテクチャは柔軟で、Wishbone と AHB をサポートします。
- この設計により、電力とサイズが最適化されます。
- 設計は完全にパラメーター化されており、パフォーマンスまたは消費電力のトレードオフを提供します。
- 電力を削減するためのゲーテッド CLK デザイン。
- 業界標準によるソフトウェア サポート。
- 建築シミュレーター。
- Linux/Windows では Eclipse IDE を使用します。
RISC V 実行パイプライン
IF (命令フェッチ)、ID (命令デコード)、EX (実行)、MEM (メモリ アクセス)、WB (レジスタ ライトバック) の 5 つのステージが含まれます。
命令フェッチ
命令フェッチまたは IF ステージでは、1 つの命令がプログラム カウンター (PC) と命令メモリから読み取られ、次の命令に更新されます。
命令プリデコード
RVC サポートが許可されると、Instruction Pre-Decode ステージが 16 ビット圧縮命令をネイティブ 32 ビット命令にデコードします。
命令デコード
命令デコード (ID) ステージでは、レジスタ ファイルが許可され、バイパス コントロールが決定されます。
実行する
実行ステージでは、ALU、DIV、MUL 命令の結果、ストアまたはロード命令に許可されたメモリが計算され、分岐とジャンプが予想される結果に対して測定されます。
メモリー
このメモリ ステージでは、パイプラインを介してメモリにアクセスします。このフェーズを含めることで、パイプラインの高いパフォーマンスが保証されます。
返事を書く
このステージでは、実行ステージの結果がレジスタ ファイルに書き込まれます。
分岐予測子
このプロセッサには、特定の分岐が行われるかどうかを決定する際にRISC Vプロセッサを導くために過去のデータを格納するために使用される分岐予測ユニットまたはBPUが含まれています。この予測データは、分岐が実行されると単純に更新されます。
このユニットには、その動作を決定するさまざまなパラメーターが含まれています。たとえば、HAS_BPU は分岐がユニットの存在を予測するかどうかを決定するために使用され、BPU_GLOBAL_BITS は過去のビット数を使用する必要があるかどうかを決定し、BPU_LOCAL_BITS はプログラム カウンターの LSB の何個を使用する必要があるかを決定します。 BPU_LOCAL_BITS と BPU_GLOBAL_BITS の組み合わせにより、主に Branch-Prediction-Table のアドレス指定に使用されるベクトルが作成されます。
データキャッシュ
これは主に、メモリの新しくアクセスされた場所をバッファリングすることにより、データメモリのアクセスを高速化するために使用されます。これは、XLEN = 32 が独自の境界上にある場合、ハーフワード、バイト、およびワード アクセスを処理できます。また、XLEN=64 の場合、ハーフワード、バイト、ワード、およびダブルワード アクセスが独自の境界上にある場合、それらを処理することもできます。
キャッシュミスの間、ブロック全体をメモリに書き戻すことができるため、必要に応じて、新しいブロックをキャッシュにロードできます。 DCACHE_SIZE をゼロに設定すると、データ キャッシュが無効になります。その後、メモリ位置は、 データインターフェース .
命令キャッシュ
これは主に、新しくフェッチされた命令をバッファリングすることにより、命令のフェッチを高速化するために使用されます。このキャッシュは、任意の 16 ビット境界でサイクルごとに 1 つのパーセルをフェッチするために使用されますが、ブロック境界を越えては使用されません。キャッシュ ミスの間、命令メモリからブロック全体をロードできます。このキャッシュの構成は、ユーザーのニーズに基づいて行うことができます。キャッシュのサイズ、置換アルゴリズム、およびブロック長は構成可能です。
ICACHE_SIZE を 0 に設定すると、命令サイクルが無効になります。その後、パーセルはメモリから直接フェッチされます。 命令インターフェース。
デバッグユニット
デバッグ ユニットにより、デバッグ環境が停止し、CPU を調べることができます。これの主な機能は、分岐トレース、最大 8 つのハードウェア ブレークポイントまでのシングル ステップ トレースです。
登録ファイル
これは、X0 から X31 までの 32 のレジスタ ロケーションで設計されており、X9 レジスタは常にゼロです。レジスタ ファイルには、1 つの書き込みポートと 2 つの読み取りポートが含まれます。
設定可能なインターフェース
これは、このプロセッサがさまざまな外部バス インターフェイスをサポートする外部インターフェイスです。
RISC V はどのように機能しますか?
RISC-V は、RISC (縮小命令セット コンピューター) の原則に基づく命令セット アーキテクチャです。このプロセッサは、ハードウェアを開発し、ソフトウェアを移植し、それをサポートするようにプロセッサを設計できる、無料で一般的なオープンソースの ISA であるため、非常にユニークで革新的です。
B/W RISC V と MIPS の違い
RISC V と MIPS の違いは次のとおりです。
|
RISC V |
MIPS |
| RISC V という用語は、Reduced Instruction Set Computer の略で、「V」は第 5 世代です。 | 「MIPS」という用語は、「1 秒あたりのミリオン インストラクション」の略です。 |
| RISC-V は、より小型のデバイスのメーカーが、お金を払わずにハードウェアを設計できるようにするだけです。 | MIPS は無料ではないため、メーカーは有料でプロセッサの速度を測定できます。 |
| MIPS は効果的に死んでいます。 | RISC-V は効率的に死んでいるわけではありません。 |
| このプロセッサは、2 つのレジスタを比較するための分岐命令を提供します。 | MIPS は、コントラストが真かどうかに基づいてレジスタを 1 または 0 に配置する比較命令に依存します。 |
| RISC V では、ISA エンコード方式は固定および可変です。 | ISA エンコーディング スキームは MIPS で固定されています |
| 命令セットのサイズは、16 ビットまたは 32 ビットまたは 64 ビットまたは 128 ビットです。 | 命令セットのサイズは 32 ビットまたは 64 ビットです。 |
| 32個の汎用および浮動小数点レジスタがあります | 31 個の汎用および浮動小数点レジスタがあります。 |
| 26 の単精度および倍精度浮動小数点演算があります。 | 15 の単精度および倍精度の浮動小数点演算があります。 |
B/W RISC V と ARM の違い
RISC V と ARM の違いには、次のようなものがあります。
|
RISC V |
腕 |
| RISC-V はオープン ソースであるため、ライセンスは必要ありません。 | ARM はクローズド ソースであるため、ライセンスが必要です。 |
| これは新しいプロセッサ プラットフォームであるため、ソフトウェアおよびプログラミング環境のサポートはごくわずかです。 | ARM には非常に大規模なオンライン コミュニティがあり、マイクロプロセッサ、マイクロコントローラ、およびサーバーなどのさまざまなプラットフォームでターゲット設計者を支援するライブラリと構造をサポートしています。 |
| RISC V ベースのチップは 1 ワットの電力を使用します。 | ARM ベースのチップは 4 ワット未満の電力を使用します。 |
| 固定および可変 ISA エンコーディング システムを備えています。 | 固定の ISA エンコーディング システムを採用しています。 |
| RISC V 命令セットのサイズは、16 ビットから 128 ビットの範囲です。 | その命令サイズは、16 ビットから 64 ビットの範囲です。 |
| 32 個の汎用 & 浮動小数点レジスタが含まれています。 | 31 個の汎用 & 浮動小数点レジスタが含まれています。 |
| 26 の単精度浮動小数点演算があります。 | 33 の単精度浮動小数点演算があります。 |
| 26 の倍精度浮動小数点演算があります。 | 29 の倍精度浮動小数点演算があります。 |
RISC V Verilog コード
RISC の命令メモリ Verilog コードを以下に示します。
// RISC プロセッサの Verilog コード
/// 命令メモリの Verilog コード
モジュール Instruction_Memory(
入力[15:0] PC、
output[15:0] 命令
);
reg [`col – 1:0] メモリ [`row_i – 1:0];
ワイヤ [3 : 0] rom_addr = pc[4 : 1];
イニシャル
始める
$readmemb(“./test/test.prog”, メモリ,0,14);
終わり
割り当て命令=メモリ[rom_addr];
エンドモジュール
16 ビット RISC V プロセッサの Verilog コード:
モジュール Risc_16_bit(
入力クロック
);
ワイヤー ジャンプ、bne、beq、mem_read、mem_write、alu_src、reg_dst、mem_to_reg、reg_write;
ワイヤー[1:0] alu_op;
[3:0] オペコードを配線します。
// データ経路
Datapath_Unit DU
(
.clk(clk)、
.jump(ジャンプ)、
.frog(カエル)、
.mem_read(mem_read),
.mem_write(mem_write),
.alu_src(alu_src),
.reg_dst(reg_dst)、
.mem_to_reg(mem_to_reg)、
.reg_write(reg_write)、
.bne(ブネ)、
.alu_op(alu_op),
.opcode(オペコード)
);
// コントロールユニット
Control_ユニット制御
(
.opcode(オペコード)、
.reg_dst(reg_dst)、
.mem_to_reg(mem_to_reg)、
.alu_op(alu_op)、
.jump(ジャンプ)、
.bne(ブネ)、
.frog(カエル)、
.mem_read(mem_read),
.mem_write(mem_write),
.alu_src(alu_src),
.reg_write(reg_write)
);
エンドモジュール
命令セット
RISC V 命令セットについては、以下で説明します。
算術演算
RISC V 算術演算を以下に示します。
| ニモニック | タイプ | 命令 | 説明 |
| 追加 rd、rs1、rs2 |
R |
追加 | rdß rs1 + rs2 |
| サブ rd、rs1、rs2 |
R |
減算 | rdß rs1 – rs2 |
| ADDI rd、rs1、imm12 |
私 |
即時追加 | rdß rs1 + imm12 |
| SLT rd、rs1、rs2 |
R |
未満に設定 | rdß rs1 -< rs2 |
| SLTI rd、rs1、imm12 |
私 |
即時未満に設定 | rdß rs1 -< imm12 |
| SLTUrd、rs1、rs2 |
R |
unsigned 未満に設定 | rdß rs1 -< rs2 |
| SLTIU rd、rs1、imm12 |
私 |
直後の unsigned 未満に設定 | rdß rs1 -< imm12 |
| LUI rd、imm20 |
の |
アッパー即時ロード | rdß imm20<<12 |
| AUIP rd,imm20 |
の |
上位即値を PC に追加 | rdß PC+imm20<<12 |
論理演算
RISC V の論理演算は次のとおりです。
| ニモニック | タイプ | 命令 | 説明 |
| および rd、rs1、rs2 |
R |
と | rdß rs1 & rs2 |
| またはrd、rs1、rs2 |
R |
また | rdß rs1 | rs2 |
| XOR rd、rs1、rs2 |
R |
自由 | rdß rs1 ^ rs2 |
| ANDI rd、rs1、imm12 |
私 |
そして即時 | rdß rs1 & imm2 |
| ORI rd、rs1、imm12 |
私 |
または即時 | rdß rs1 | imm12 |
| OXRI rd、rs1、imm12 |
私 |
XOR 即時 | rdß rs1 ^ rs2 |
| SLL rd、rs1、rs2 |
R |
論理左シフト | rdß rs1 << rs2 |
| SRL rd、rs1、rs2 |
R |
論理右シフト | rdß rs1 >> rs2 |
| RAS rd、rs1、rs2 |
R |
右シフト算術 | rdß rs1 >> rs2 |
| SLLI rd、rs1、シャム |
私 |
論理即値左シフト | rdß rs1 << シャム |
| SRLI rd、rs1、シャムト |
私 |
右シフト論理即値 | rdß rs1 >> シャム |
| SRAI rd、rs1、シャムト |
私 |
算術即値右シフト | rdß rs1 >> シャム |
ロード/ストア操作
RISC V のロード/ストア操作を以下に示します。
| ニモニック | タイプ | 命令 | 説明 |
| LD rd、imm12 (rs1) |
私 |
ダブルワードをロード | rdß メモリ [rs1 +imm12] |
| LW rd、imm12 (rs1) |
私 |
単語を読み込む | rdß メモリ [rs1 +imm12] |
| LH rd、imm12 (rs1) |
私 |
途中までロード | rdß メモリ [rs1 +imm12] |
| LB rd、imm12 (rs1) |
私 |
ロードバイト | rdß メモリ [rs1 +imm12] |
| LWU rd、imm12 (rs1) |
私 |
符号なしで単語をロード | rdß メモリ [rs1 +imm12] |
| LHU rd、imm12 (rs1) |
私 |
ハーフワードを符号なしでロード | rdß メモリ [rs1 +imm12] |
| LBU rd、imm12 (rs1) |
私 |
符号なしバイトをロード | rdß メモリ [rs1 +imm12] |
| SD rs2、imm12 (rs1) |
S |
ダブルワードを格納 | rs2 から mem [rs1 +imm12] |
| SW rs2、imm12 (rs1) |
S |
ストアワード | rs2 (31:0) から mem [rs1 +imm12] |
| SH rs2、imm12 (rs1) |
S |
途中まで保存 | rs2 (15:0) から mem [rs1 +imm12] |
| SB rs2、imm12 (rs1) |
S |
格納バイト | rs2 (15:0) から mem [rs1 +imm12] |
| SRAI rd、rs1、シャムト |
私 |
算術即値右シフト | rs2 (7:0) から mem [rs1 +imm12] |
分岐操作
RISC V の分岐操作は次のとおりです。
| ニモニック | タイプ | 命令 | 説明 |
| BEQ rs1、rs2、imm12 |
SB |
ブランチ イコール | rs1== rs2 の場合 PC ß PC+imm12 |
| BNE rs1、rs2、imm12 |
SB |
ブランチが等しくない | rs1!= rs2 の場合 PC ß PC+imm12 |
| BGE rs1、rs2、imm12 |
SB |
以上のブランチ | rs1>= rs2 の場合 PC ß PC+imm12 |
| BGEU rs1、rs2、imm12 |
SB |
符号なし以上の分岐 | rs1>= rs2 の場合 PC ß PC+imm12 |
| BLT rs1、rs2、imm12 |
SB |
未満のブランチ | rs1 |
| BLTU rs1、rs2、imm12 |
SB |
未署名未満の分岐 | rs1 |
| JAL rd, imm20 |
UJ |
ジャンプしてリンク | rdβPC+4 PCß PC+imm20 |
| JALR rd、imm12(rs1) |
私 |
ジャンプとリンクレジスタ | rdβPC+4 PCβ rs1+imm12 |
利点
の RISCの利点 V プロセッサー 以下のものが含まれます。
- RISCVを使用することで、開発時間、ソフトウェア開発、検証などを節約できます。
- このプロセッサには、シンプルさ、オープン性、モジュール性、白紙の設計、拡張性など、多くの長所があります。
- これは、GCC (GNU Compiler Collection) などのいくつかの言語コンパイラ、フリーソフトウェア コンパイラ、および Linux OS .
- これは、ロイヤリティ、ライセンス料、および関連する文字列がないため、企業が自由に使用できます。
- RISC-V プロセッサには、確立された RISC の原則に従っているだけなので、新しい機能や革新的な機能は含まれていません。
- 他のいくつかの ISA と同様に、このプロセッサ仕様はさまざまな命令セット レベルを定義するだけです。したがって、これには 32 ビットおよび 64 ビットのバリアントと、浮動小数点命令をサポートするための拡張機能が含まれています。
- これらは、無料、シンプル、モジュール式、安定版などです。
短所
の RISC V プロセッサの短所 以下のものが含まれます。
- 複雑な命令は、コンパイラとプログラマによって頻繁に使用されます。
- RISC の o/p は、ループ内の後続の命令が実行のために前の命令に依存する場合、コードに基づいて変更される場合があります。
- これらのプロセッサは、さまざまな命令を迅速に保存する必要があります。これには、命令にタイムリーに応答するための大きなキャッシュ メモリ セットが必要です。
- RISC の完全な機能、機能、および利点は、主にアーキテクチャに依存します。
アプリケーション
の RISC V のアプリケーション プロセッサ 以下のものが含まれます。
- RISC-V は、組み込みシステム、人工知能、機械学習で使用されています。
- これらのプロセッサは、高性能ベースの組み込みシステム アプリケーションで使用されます。
- このプロセッサは、エッジ コンピューティング、AI、ストレージ アプリケーションなどの特定の分野での使用に適しています。
- RISC-V は、小規模なデバイス メーカーが費用を負担せずにハードウェアを設計できるようにするため、重要です。
- このプロセッサにより、研究者や開発者は自由に利用できる ISA または命令セット アーキテクチャを使用して設計および研究を行うことができます。
- RISC V のアプリケーションは、小型の組み込みマイクロコントローラからデスクトップ PC やベクトル プロセッサを含むスーパーコンピュータにまで及びます。
したがって、これは RISC V プロセッサの概要 – アーキテクチャ、アプリケーションの操作。ここで質問があります。CISC プロセッサとは何ですか?
![IC4060ラッチングの問題[解決済み]](https://electronics.jf-parede.pt/img/timer-delay-relay/35/ic-4060-latching-problem.jpg)